Data Visualization Analyses
By Kenyon Geetings
Analysis 1
Assignement Instructions
Find a data visualization related to a topic you are interested in, and analyze it using the concepts from Chapter 1, especially the perceptual rankings, Gestalt principles, and preattentive processing. Begin with a description of what is communicated by the visualization, apply the principles from Chapter 1, and then conclude with your assessment of how effective the visualization is based on these principles. Include an image of the visualization and a URL reference.
Analysis 1 - The Pocket Paradox
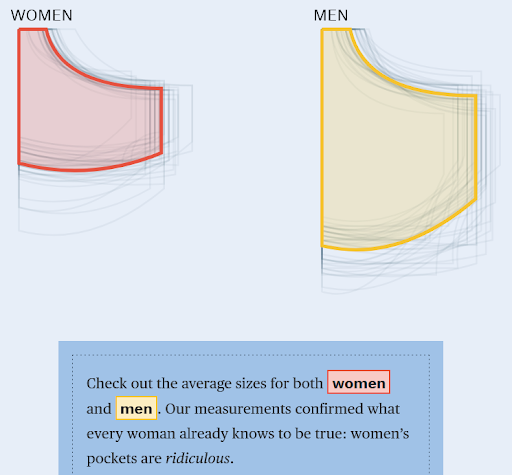
In the contemporary world, gender disparities extend well beyond the realms of workplaces and educational institutions. They permeate even the most subtle aspects of our daily lives, such as the seemingly innocuous size of pockets in clothing. In this analysis, we will closely examine a data visualization that aims to bring to light the disparities in average pocket sizes between men and women. This visualization employs a range of design elements, including color, position, and size, to effectively convey this information. To gauge its effectiveness in communicating the intended message, we will evaluate this visualization through the lenses of perceptual rankings, Gestalt principles, and preattentive processing.
The data visualization under scrutiny presents a rectangular canvas divided into two distinct halves. The left half represents women's pocket sizes, while the right half signifies men's pocket sizes. Notably, women's average pocket size is marked in a striking red hue, while men's average pocket size is represented by a vibrant shade of yellow. These contrasting colors immediately capture the viewer's attention and serve as focal points. Each gender's average pocket size is additionally emphasized by a darker outline in their respective colors. Beneath these colored averages, a series of smaller gray outlines portrays individual pocket sizes contributing to the overall average.
Firstly, let's explore perceptual rankings, which pertain to how our brains naturally prioritize visual elements and perceive data values. In this visualization, the use of area to imply differences between men's and women's pockets may not provide the most precise estimates. However, it does succeed in engaging the viewer's curiosity and inviting them to delve deeper into the data. Importantly, the decision to steer clear of conventional bar or line graphs, while potentially sacrificing pinpoint accuracy, preserves visual appeal and clarity. The visualization strikes a balance that effectively conveys the intended data without the need for cluttering legends or axes.
The Gestalt principles explore how we perceive and group visual elements to form a coherent whole. In this visualization, the principle of proximity is applied. The individual pocket sizes beneath each average are grouped closely together, reinforcing the idea that they contribute to the respective gender averages. This proximity enhances the viewer's ability to compare individual pocket sizes effectively.
Preattentive processing, our ability to rapidly and subconsciously analyze visual elements, plays a significant role in this visualization. Color, in particular, is a potent tool here. The vibrant yellow and red hues prominently contrast against the backdrop of blue, immediately capturing viewers' attention. Consequently, the color choices and the use of outlines effectively make the average pocket sizes immediately discernible, emphasizing gender-based disparities. Furthermore, viewers can quickly ascertain which side represents men's pockets and which represents women's, thanks to the positioning of the outlines, facilitating swift and effortless comprehension of the gender disparity.
In summary, this data visualization effectively communicates the average sizes of women's and men's pockets, with individual sizes depicted beneath the respective averages in gray. By incorporating the principles of perceptual rankings, Gestalt principles, and preattentive processing, we can assess its effectiveness comprehensively.
The utilization of color (yellow for averages and gray for individual sizes) aligns seamlessly with perceptual rankings, effectively highlighting critical data points. The application of the Gestalt principle of proximity in grouping individual pocket sizes with their respective averages aids the comparison process significantly. Leveraging preattentive processing through the strategic use of yellow and red ensures that viewers can readily grasp the core message.
In conclusion, this data visualization succeeds in conveying gender disparities in pocket sizes. It skillfully leverages well-established principles of perception and attention to create a clear and impactful message. However, for a more comprehensive understanding of the data, the visualization could benefit from additional context or labels, such as specifying the measurements of average pocket sizes for men and women. Fortunately, such supplementary information is available on the website, including intriguing visualizations involving phone and hand size overlays. In its entirety, this visualization serves as a compelling representation of a subtle yet significant facet of gender inequality in our daily lives.
Analysis 2
Assignement Instructions
Find a data visualization related to a topic you are interested in, and analyze it using what we have learned so far, through color on 8/31. Begin with a description of what is communicated by the visualization, apply the principles you have learned, and then conclude with your assessment of how effective the visualization is based on these principles. Include an image of the visualization and a URL reference.
Analysis 2 - Topping the Charts

The data visualization under scrutiny within the context of analysis two presents a line chart illustrating the "Repetition of Popular Music, by Year." The chart encompasses two distinctive lines: a blue line symbolizing the entirety of songs and a yellow line denoting the top ten songs for each year. Notably, 2014 exhibits a pronounced peak, signifying the most repetitive year on record. The fundamental trend discerned from the years 1960 to 2015 indicates that, on average, the top ten songs were more repetitive every year. This paper embarks on an exploration of this data visualization through the prism of perceptual rankings, Gestalt principles, preattentive processing, and the strategic use of colors to assess its efficacy in conveying information.
Perceptual rankings assume a pivotal role in the realm of data visualizations as they steer viewers' attention toward salient information. In this instance the employment of a line chart shows positions along a common scale and according to the perceptual ranking diagram enables accurate estimates. Given that the reader is already immersed in the data, having perused approximately half of this report, delving into deeper analysis permits a quick yet effective evaluation of the progression of song repetitiveness. In this context, the two-line chart divulges all pertinent information transparently, offering readers the option to swiftly navigate through and glean relevant insights or embark on a more profound exploration of each year's averages.
Gestalt principles, which describe how we perceive and organize visual elements, are essential in understanding how viewers interpret data visualizations. One key principle at play here is the principle of similarity. The use of the same style of line chart for both the top ten and all songs, suggests a similarity and correlation in their nature, reinforcing the idea that they represent related data points. Moreover, the distinct colors reinforce the principles of similarity and connection, as viewers automatically categorize each line into its designated section, aiding in the seamless tracking of individual years.
Preattentive processing refers to the rapid, unconscious perception of visual elements before focused attention is applied. While you scroll down the page, before the line chart is fully displayed, the website offers several overlays explaining parts of the chart. The designer chooses not to draw the entire chart until after you scroll past the overlays, and this strategic approach permits the preattentive processing attributes of markings to take effect. However, it is worth noting that this visualization does not heavily rely on preattentive processing techniques to convey its message.
While this part might not fit into one of the four categories, I think it would be disingenuous to not call attention to where this chart starts its axis. In this visualization, the y-axis range, spanning from 40% to 60%, could potentially be misleading. Preattentively, but not to be confused with preattentive processing, viewers might assume that the chart begins at 0%, which would be the norm for many types of graphs. However, the intentional choice of this truncated y-axis scale can be seen as an attempt to emphasize subtle differences between the lines, and this idea is further backed up in chapter five which claims the axis of a line chart does not need to start at zero. Still, it may lead to misinterpretations if viewers do not scrutinize the axis closely. This design choice seems to go against the principles of inherent bias, as it may cause initial misperceptions about the data's magnitude.
Color is a powerful tool in data visualization and can enhance or detract from the effectiveness of the chart. In this case, the use of blue and yellow is effective in distinguishing between the two datasets. Yellow, being a high-contrast color against the white background, draws immediate attention, indicating the significance of the top ten songs. The use of a muted blue for the remaining songs complements the prominence of the yellow line without overpowering it. The use of yellow and blue adheres to the categorical color palette, signifying nominal differences, as neither the top ten nor all songs hold superior importance within this graphic.
In conclusion, the data visualization of the "Repetition of Popular Music, by Year" effectively employs perceptual rankings, Gestalt principles, and color to convey information. It appropriately highlights the top ten songs using a distinct color and maintains consistency in the visual elements. However, the choice of a truncated y-axis scale, while potentially aiding in highlighting subtle differences, may also lead to initial misperceptions about the data's magnitude, which could be seen as a slight deviation from the otherwise commendable principles that underpin this graphic. To improve the effectiveness of this visualization, a more standard y-axis scale could be considered, ensuring that viewers interpret the data accurately at first glance. In summary, this visualization skillfully conveys the evolution of popular music repetitiveness over the years, but minor adjustments could further enhance its clarity and impact.
Analysis 3
Assignement Instructions
Find two visualizations related to topics you are interested in that use two of the idioms bar chart, line chart, histogram, or box plot. (They do not have to be related.) Write a short analysis of each using concepts from the corresponding chapter in Schwabish. Include descriptions of your data attributes, their types (categorical, quantitative, etc.), and how each is displayed (the visual channel). Also apply what you have learned about color, as well as principles from Chapters 1 and 2. Be thorough but concise in analyzing the overall effectiveness of each visualization. Include an image of each visualization and its full URL reference.
Analysis 3 - Striking a Chord: Visualizing Gender Dynamics in Country Music
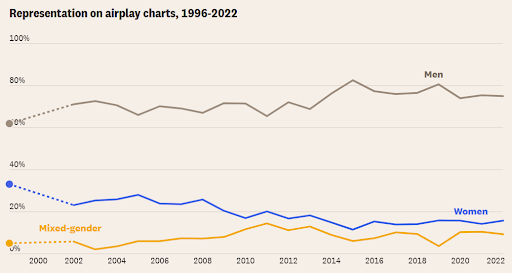
The first visualization is a line chart titled "Representation on airplay charts, 1996-2022." This line chart effectively displays the representation of men, women, and mixed-gender artists on country radio airplay charts over the years. The data attributes in this chart are primarily discretely quantitative, representing the percentage of songs by each gender category on the airplay charts, where the count of a song cannot be subdivided.
The visual channel of this line chart employs three distinctive lines, each represented by a different color scheme: a subdued gray line signifies male artists, a vibrant blue line represents female artists, and a striking yellow line denotes mixed-gender collaborations. The lines are mostly continuous, and the years are plotted on the x-axis, while the percentage representation is plotted on the y-axis. The choice of color in this chart adheres with the guidelines articulated in Chapter 2, specifically starting with gray, as it uses a muted gray for the men contrasted with vibrant blue and yellow to accentuate the underrepresentation of women in the genre. It also does a good job of integrating the graphics and the text by removing legends and labeling the data directly, but they don’t align the labels like the book suggests.
This chart adeptly adheres to the principles delineated in Chapter 1 as well. It harnesses the power of preattentive processing by employing distinctive colors for each gender category, rendering data differentiation and grouping effortlessly discernible at a cursory glance. Furthermore, it facilitates precise estimations in accordance with the perceptual rankings diagram. An insightful feature of this chart is the employment of a dotted line during the years 1999-2001, which illustrates the use of less comprehensive data with visual cues. Noteworthy is the fact that these discontinuities do not denote data gaps but rather correspond to the period when Billboard began incorporating additional metrics.
Overall, this line chart effectively conveys the consistent trends in gender representation on country radio airplay charts over time. It is clear, visually appealing, and follows essential principles of data visualization, making it an excellent tool for understanding the historical context of gender representation in the country music industry.
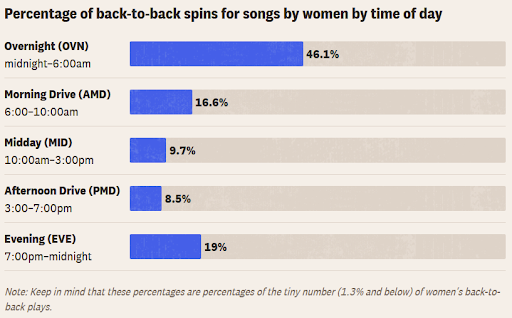
The second visualization is a bar chart titled "Percentage of back-to-back spins for songs by women by time of day." This chart aims to showcase the distribution of songs by women played back-to-back on country radio at different times of the day.
The data attributes in this chart are also discretely quantitative, representing the percentage of back-to-back plays for songs by women at various times of the day. The visual channel chosen is a bar chart, where each bar is a distinct temporal segment of the day. With the filled part of the bars in blue and the unfilled parts in gray, we quickly ascertain that songs by women are played back to back more often during the night, presumably coinciding with reduced listener counts.
An interesting design choice in line with the principles established in Chapter 2 is the omission of a traditional y-axis, replaced instead by placing percentage values adjacent to the blue, filled sections of the bars. However, this chart lacks an active headline title where the author has instead opted to use a more neutral description of the data.
In terms of perceptual ranking, preattentive processing and the Gestalt principles, the bar chart lies at the top of the ranking diagram, which means that it enables accurate estimations of the data. The author chooses not to actively use the principle of continuity, but rather provides clear enclosures between each time range. The use of the color blue for each bar harnesses the preattentive attribute of color to swiftly convey percentages and to underscore that the data is representative of a complete day.
While the chart does effectively show the variation in back-to-back spins for songs by women across different times of the day, it could benefit from improved clarity and adherence to some fundamental data visualization principles. Enlarging the minor note positioned at the chart's bottom would serve to emphasize the potential for misleading interpretations, enhancing overall transparency.
In summary, both visualizations provide valuable insights into gender representation on country radio airplay charts and the timing of songs by women. However, the second visualization could be refined for better clarity and adherence to data visualization principles.
Analysis 4
Assignement Instructions
Find a visualization that you think you could improve, and analyze its strengths and weaknesses based on the principles you have learned so far. Evaluate its overall effectiveness and then describe what you would do to improve it. Include an image of the visualization and its full URL reference.
Analysis 4 - 2018 PFA Bee Collections
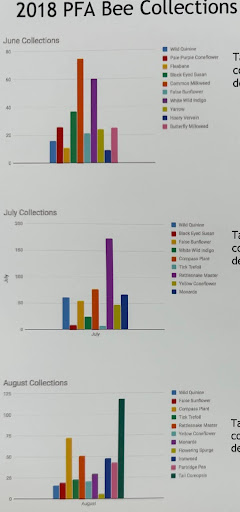
This chart was crafted by Central students Parker Hill, Benjamin Turnley, Will Daniels, and Sarah Casterline. The poster's title is “Native Bees of Iowa: Who Are They and How to Attract Them.” These three graphics come together to show a story spanning three months of PFA Bee Collections over summer 2018. While the acronym PFA, representing “Prairies for Agriculture,” is not explicitly articulated in either the poster or its accompanying visuals, it has been ascertained through my analysis of this graphic.
Several noteworthy deficiencies are observed within each of these bar charts. Firstly, a lack of consistency is evident, as the coloration of plants varies from one month to another. Moreover, only two of the charts feature an x-axis title, while one remains devoid of this element. Interestingly, the range of the y-axis differs significantly across all these charts.
A discerning examination of the perceptual rankings diagram reveals a curious choice on the part of the creators. Although bar charts were employed, they opted for positions along non-aligned, identical scales. While this choice enhances the potential for accurate estimation, it falls short of achieving perfection in this category.
The rationale behind the order and coloration of plants, both within individual charts and across all three, appears arbitrary and lacks a clear basis. In this aspect, the creators seem to have adhered to the correct principle by using categorical colors that suit the categorical nature of the data. Nevertheless, a more judicious choice could have been to start with a neutral gray to minimize extraneous visual distractions and emphasize key information.
Additionally, the integration of graphics and text in this presentation leaves room for improvement. While this may not pose a significant challenge with bar charts in general, the lack of consistent order could have warranted data labels directly integrated within the charts, rather than relying on a legend.
While the creators deserve credit for starting the axis at zero and avoiding breaking the bars, they could substantially enhance readability by considering the rotation of the x and y axes. This, combined with the integration of labels into the graphical elements, would significantly improve the overall legibility of these charts.
In summary, this graphic exhibits considerable potential but ultimately falls short of exemplifying a well-constructed visualization. Addressing these deficiencies would enhance its effectiveness in conveying information and insights to the audience.
Analysis 5
Assignement Instructions
Find a visualization that uses one of the more complex idioms we have studied recently in Chapters 4 through 7, and analyze its effectiveness based on everything you have learned so far. Be thorough but concise. Include an image and a full URL reference.
Analysis 5 - Coloring Outside the Birthday Lines: An Amusing Visual Tale

The first visualization, titled "How Common is Your Birthday," utilizes a heatmap to display data related to the frequency of birthdays across different months. In this visualization, the color blue represents the least common birthdays, while pink signifies the most common ones. The data attribute being visualized here is the distribution of birthdays across months, making it a categorical variable.
In terms of the principles from Schwabish's book, this visualization effectively uses color to highlight differences in birthday frequencies. However, there are some issues with this visualization. The heatmap suggests a greater level of variation in birthday frequencies than there actually is. This discrepancy may be attributed to the dataset's limitations – it appears that the dataset is relatively small and might not sample enough years. This underlines the importance of data integrity and sample size to ensure accurate and reliable visualizations. Additionally, while the visualization is aesthetically pleasing, it might mislead viewers due to the exaggerated color contrast.
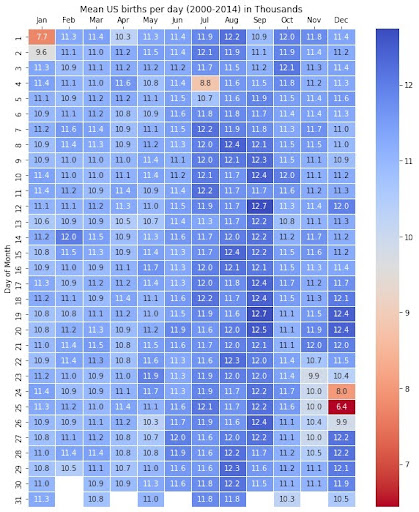
The second dataset addresses the issues in the first visualization by spanning 14 years (2000-2014) to provide a more comprehensive view of birthday frequencies. Again, a heatmap is used to display the data. The dataset's attribute remains categorical, representing the distribution of birthdays across months.
This second visualization effectively ameliorates the issues of the limited dataset in the first one by expanding the time range, leading to more accurate insights. The color is still used effectively to convey information. Notably, this visualization makes January 1st, July 4th, and December 24/25 stand out as the least common birthdays, aligning with the principles of preattentive processing by clearly showing a difference in color.
While I believe that both of these visualizations are good for their respective applications, I think it would have been interesting to see these done as the example in the book where Schwabish modified the layout and applied it to a calendar year. This expanded view would be easier to look at but since this data is taken over several years, you would not be able to utilize the weekdays like done in the book. I think both visualizations avoid clutter and spaghetti chart issues by focusing on relevant data but the second one does a better job of enabling general estimates through the more careful use of shading and saturation by calling attention to only a few dates that are truly different from the rest. It is clear to me that the second graphic’s creator started with gray and chose to add color in a more meaningful way than the first graphic did.
In summary, the first visualization, while aesthetically pleasing, is limited by a small dataset and may exaggerate variations in birthday frequencies. The second visualization, by spanning 14 years, provides a more accurate representation of the data, and it effectively highlights the least common birthdays. Both visualizations make effective use of color and adhere to principles from Schwabish's book, but the second one improves upon the shortcomings of the first by presenting a more reliable and informative view of the data.